

Алексей Федорчук
Fedoriada, 04.04.2011
Первый вариант этого материала, в виде серии заметок, сочинялся весной 2011 года. Стех пор кое-что улучшилось, в частности, tesseract. С тех пор я с распознаванием текстов имел дело только от случая к случаю — это не то, чем хочется заниматься без практического повода, а таковые, хвала Ахурамазде, были очень редко. Но принципиальных изменений и каких-либо прорывов, насколько я знаю, не произошло. Материал размещается as were, с некоторыми модификациями, отражающими реалии сего дня.
Как известно, распознавание текстов, особенно кириллических, никогда не было сильной стороной мира FOSS (и, в частности, Linux’а): до недавнего времени средства для этого, мягко говоря, оставляли желать лучшего. Однако нынче наметились положительные сдвиги в этом направлении, что я и постараюсь продемонстрировать в предлагаемом материале.
- Постановка задачи
- Инструментарий для сканирования
- Инструментарий для распознания
- Проприетарное отступление
- Scan Tailor — предобработчик сканов
- Распознание посредством YAGF
- На свободу с tesseract
Постановка задачи
Долгое время мне казалось, что свободные программы OCR вообще и для Linux в частности — штука абсолютно не актуальная. Большая часть старого «бумажного» контента уже оцифрована, то, что осталось неокученным — постепенно распознают вендузяднеги со своим FineReader’ом, а весь новый контент создаётся в цифровом виде и в распознавании не нуждается.
Однако столкновение с реальностью показало мою неправоту. В связи с развитием одного из своих проектов я начал смотреть, что же есть в сети из старых исторических трудов. Оказалось — далеко не всё, для меня интересное. А немало того, что таки есть — существует в формате DjVu. Который, конечно, незаменим для точного воспроизведения исторических источников, но не самый подходящий для чтения работ современных историков.
Что же до контента нового — при сборе материалов о советской геологии неоднократно возникали ситуации, когда некий «бумажный», но набранный заведомо на компьютере, текст проще было перенабрать, нежели заполучить цифровой исходник.
Это было второй причиной, почему я занялся OCR. Первая же блестяще демонстрировала всю силу тезиса профессора Выбегаллы о развитии духовных потребностей в соответствие с материальными. А именно, по случаю обзаведясь МФУ (HP DeskJet 2050), то есть удовлетворив материальную потребность, я ощутил непреодолимую тягу к развитию потребности духовной — каким-то образом использовать его в мирных целях (помимо сканирования и распечатки некоторых бюрократических бумажек).
Вот для удовлетворения духовной потребности я вспомнил о неоцифрованных материалах, залежавшихся у меня на книжных полках. Разумеется, прежде чем брать в руки олимпийский мяч — по настоящему старые книги начала прошлого века, — было естественно потренироваться сначала в тряпичный — книги не такие уж и старые.
В связи с сочинением пиктского цикла (ныне это электронная книжка Пикты и их эль в Библиотеке Блогосайта) вспомнилось мне об учебном пособии Галины Ивановны Зверевой История Щотландии, изданной в 1987 году в серии «Библиотека историка». Благо,
- несмотря на марксистско-ленинскую направленность (а чего вы хотите от учебного пособия 80-х годов розливу?), она могла быть неплохим введением в предмет,
- сохранность её была относительно не из худших, и
- раздельчик её, имеющий отношение к пиктам, насчитывал всего с дюжину страниц (а именно — с 5-й по 18-ю).
То есть в качестве тренировочного объекта она вполне годилась. Так что я засучил рукава и принялся за работу.
Инструментарий для сканирования
Для сканирования и распознавания текстов в первую очередь требуется, естественно, сканер, во-вторую — сканер работающий под управлением Linux’а (в данном случае — Fedora). В очередь же третью необходимо программное обеспечение для сканирования. Первая задача решается «чэрэз магазын» (и не обязательно его задний кирилцо). Мной она была решена посредством приобретения МФУ HP Dj 2050 (которое служит мне в своей скнирующей части и по сей день).
Решение второй задачи — заставить работать именованное устройство под Linux’ом — в дни сочинения первой версии этого материала наталкивалось иногда на некоторые сложности. Ныне же, благодаря развитию HPLIP, для устройств производства Hewlett Packard всё столь тривиально, что не заслуживает описания, ибо сводится к легендарным словам «включил — и работает». Так что далее речь пойдёт исключительно о третьей задаче. потребовала
Здесь в первую голову следует назвать sane — бэк-энд для взаимодействия со сканерами (и не только). Однако заморачиваться установкой его не придётся: практически наверняка этот пакет появился в системе уже при инсталляции, так как он вытягивается как зависимость множества программ.
А вот на счёт высокоуровневых фронт-эндов для работы со сканерами можно подумать. В стандартной установке Fedora, при использовании в качестве десктопа GNOME, XFce или LXDE , по умолчанию устанавливается программа Simple Scan, которую можно обнаружить в и в большинстве других дистрибутивов, использующих Gtk based десктопы. В системах с KDE её аналогом является SkanLite.
Simple Scan очень быстр, прост в использовании, позволяет сканировать как фотографии, так и текст:

Переключение между режимами выполняется через меню Документ -> Отсканировать или из инструментальной панели.
Есть функции элементарного редактирования — обрезки изображения (по одному из стандартных форматов бумаги или произвольно), поворота на 90o по или против часовой стрелки.
Через меню Документ -> Параметры можно выполнить выбрать источник сканирования (если есть из чего выбирать), а также установить разрешение сканирования — от 75 dpi до максимально возможного для устройства (в моём случае это 1200 dpi оптического разрешения и 2400 — интерполяционного). По умолчанию разрешение выставлено в 150 и 300 dpi — для текста и изображения, соответственно.

Отсканированное изображение может быть сохранено в форматах PDF, JPG и PNG — и более ни в каких. Причём никакие параметры для компрессированных форматов установить нет возможности.
Всё это делает Simple Scan пригодным для сканирования на скорую руку (например, для помещения в сеть). Хотя в целях распознавания простого текста, при соблюдении некоторых условий, он вполне может быть использован. Однако для более серьёзной работы с изображениями (да и для распознавания текстов в более сложных случаях) лучше поискать другие инструменты.
В скобках замечу, что сказанное в предыдущем абзаце относилось к 2011 году. Ныне Simple Scan сканирует на предмет распознавания ничуть не хуже (хотя и ничуть не лучше) всех других инструментов.
Благо их у нас есть — программа xsane, высокоуровневая оболочка, использующая все возможности sane. Она также может быть в наличии после первичной инсталляции, но если нет — её легко установить штатными средствами дистрибутива.
При запуске xsane мы видим картину вроде следующей:

Которая сразу и подсказывает направление дальнейших действий:
- определить путь к каталогу для складывания результатов сканирования и шаблон имён файлов; например, scan01 — счётчик автоматически будет наращивать номера (по умолчанию — на единицу);
- выбрать формат выходных файлов из выпадающего списка;
- задать режим сканирования: штриховой (для текста), чёрно-белый (для монохромных изображений) или цветной (для фотографий);
- указать разрешение сканирования — от 75 dpi до максимально возможного физически (у меня — 1200 dpi); ниже я скажу, почему надо ставить именно 600 dpi.

После этого остаётся только поместить в устройство «исходник» — и нажать кнопку Сканировать. Результат для текста будет более чем удовлетворительный, для фотографии — вполне приличный. Если же качество отсканированного изображения не устраивает, следует обратиться к более тонким настройкам через меню Параметры -> Настройки:
В настройках имеется специальная вкладка Распознавание текста:

Там теоретически можно, вместо какой-то умолчальной Gocr, задать собственную программу-распознаватель (например, cuneiform, о которой скоро пойдёт речь). Однако практически, как станет ясно из дальнейшего рассказа, это мало чего даст.
Инструментарий для распознания
Понаслышке я знал о существовании нескольких программ для распознавания текстов, например, о gocr — GNU OCR и GNU Ocrad. Но также доводилось мне слышать и о том, что с кириллическими текстами они то ли не работают вообще, то ли работают очень не лучшим образом. Зная «любовь» англоязычных товарищей к Великому и Могучему, я легко мог в это поверить — и потому даже не рассматривал их.
Всерьёз для распознавания кириллических текстов могла рассматриваться только программа Cuneiform производства отечественной фирмы Cognitive Technologies, о которых надо сказать несколько слов.
Сейчас уже мало кто помнит, что одной из первых OCR вообще и чуть ли не первой, приспособленной для работы с кириллицей, была программа Tiger, появившаяся на заре 90-х годов прошлого века и работавшая под DOS. С приходом отца Уындовса она была приспособлена к этой «дешёвой оболочке», результат чего получил название Cuneiform.
Некоторое время образованная в 1993 году фирма Cognitive Technologies развивала оба направления — и DOS-программу Tiger, и Win-программу Cuneiform. Причём, как это ни парадоксально, Tiger со своей непосредственной задачей — распознаванием всякого рода бюрократических бумажек — справлялся куда лучше. И, к слову сказать, успешней, чем возникший в том же 93-м FineReader производства BIT Software (в последующем и поныне — ABBYY).
В дальнейшем DOS как массовая система отмерла, а вместе с нею забылся и Tiger. Тем более, что и Cuneiform, и FineReader вполне достигли его уровня, двигаясь более-менее ноздря в ноздрю. Но затем FineReader совершил мощный рывок вперёд, и участью Cineiform стала роль довеска к некоторым моделям сканеров. А потом и эта нива засохла.
И тогда Cognitive Technologies в конце 2007 года приняла эпохальное решение — открыть исходные тексты Cuneiform под BSD-лицензией. Что и было претворено в жизнь в апреле 2008 года. Результатом стало появление в середине того же года свободных версий этой OCR под Linux, FreeBSD и MacOS X, созданных Юсси Пакканен (Jussy Pakkanen).
Порты Cuneiform под UNIX-подобные системы, в отличие от Windows-версии, не имели собственного графического интерфейса, работая исключительно из командной строки. Однако дело не стало и за графическими фронт-эндами. Ими стали:
- Cuneiform-Qt, разработанный Андреем Черепановым (посетителям Юниксфорума он известен как Skull), и
- YAGF Андрея Боровского, подробный разговор о котором впереди.
А пока вернёмся к собственно Cuneiform. Для её использования она должна быть установлена, что в большинстве дистриутивов делается их штатными средствами. Далее всё просто — в терминале даётся команда вида
$ cuneiform -l rus -f text -o out_file.txt in_file.tiff
Где опция -l явным образом задаёт язык (в примере — русский), опция -f —формат того, что должно получится на выходе (в примере — plain text), опция -o указывает имя выходного файла, а аргументом служит файл сканированного изображения страницы.
Однако если мы подсунем в указанную строку файл, напрямую полученный при сканировании страницы, то ничего доброго не получится. Во-первых, я не зря говорил в предыдущей заметке о разрешении сканирования 600 dpi — уже при 300 dpi выходной текстовый файл будет состоять из двух-трёх невнятных закорючек. Я уж не говорю о 150 умолчальных точках Simple Scan. Причём это совершенно не зависит от качества сканируемого оригинала — распознание свежераспечатанной на хорошем принтере страницы A4 завершается тем же фетсяску, что и пожелтевшей страницы книжной из довоенного издания.
При обсуждении этого вопроса в Джуйке было высказано мнение, что для использования Cuneiform сканировать надо в максимально высоком разрешении. Таковых мне доступно было два — 600 и 1200 dpi (про интерполяционные 2400 говорить не будем). Сравнение показало, что результат распознавания получается практически одинаковым, времени же на сканирование во втором случае затрачивается раза в четыре больше.
Во-вторых, даже при высоком разрешении распознание книжных страниц даёт массу ошибок, исправлять которые вручную — адский труд. Ошибки возникают от перекоса страниц, неплотного прилегания разворота книги, временных дефектов текста и так далее. Особенно скверно получается при распознавании не очень качественного русского текста с вкраплениями латиницы — символы её в лучшем случае подменяются похожими кириллическими, в худшем — тильдами, решётками и разнообразными кавычками. А уж текст с вкрапленными картинками способен просто вогнать Cuneiform в ступор, прерываемый только комбинацией Control+C.
В-третьих, теоретически в Cuneiform должна существовать возможность пакетного распознавания страниц — однако на поверхности она не валяется. И вообще, документация к этой программе по скудости может сравниться с карманом пост-советского бомжа. Что, разумеется, не облегчает её прямое использование.
Все три камня преткновения, конечно же, преодолимы. Требуемое разрешение, как я уже говорил, легко задать в любой из двух упомянутых ранее программ сканирования. Для предварительной обработки отсканированных страниц существует несколько средств, в том числе такое замечательное, как Scan Tailor. Ну а для упрощения самого распознания можно использовать какой-либо из двух упомянутых выше фронт-эндов — у меня исторически склалаось так, что я остановился на YAGF.
Проприетарное отступление
Справедливости ради следует сказать, что резонные люди рекомендуют использовать для распознания текстов под Linux’ом… FineReader для Windows, запускаемый в Wine. Говорят, что работает это хорошо, и распознаёт очень эффективно. Но я таким путём не пошёл. И не из идеологических соображений — ибо когда дело касается работы, идеология замолкает. И не из жадности — полторы тысячи рублей за Home Edition не такие уж большие деньги. И даже не из-за антипатии к Wine — для раскладывания пасьянса я им ранее не брезговал.
Нет, главная причина была сугубо практическая: мне хотелось самолично убедиться, пригоден ли свободный софт для сформулированной в самом начале цикла задачи. И, при положительном ответе, описать — каким именно образом он пригоден.
Забегая вперёд, скажу, что ответ был положительным. Хотя и с рядом существенных оговорок. Но есть надежда — кто-то из прочитавших эти материалы заинтересуется вопросом и внесёт свой вклад в то, чтобы оговорки эти снять.
Scan Tailor — предобработчик сканов
Как было только что сказано, если отсканированные страницы текста в первозданном виде скормить Cuneiform’у, результат распознания получится в лучшем случае не идеальным (в худшем — никаким). Предварительно надо избавить сканограммы от дефектов оригинала и огрехов сканирования. Сделать это можно в графическом редакторе типа GIMP’а — но опять же это средство далеко не соответствует цели. Что не составит повода для уныния ввиду наличия специализированных программ предварительной обработки отсканированных страниц.
Одна из таких программ — Scan Tailor, разработанная Иосифом Арцимовичем. Она базируется на библиотеке Qt4, распространяется под лицензией GPL 3 и доступна в бинарном виде для Windows и в исходниках — для всех остальных ОСей. Впрочем, компиляцией её заниматься совсем не обязательно — программа эта имеется в репозиториях не только Fedora, но и в большинстве более иных дистрибутивов. Так что в любом из них она может быть установлена штатными методами. В число функций Scan Tailor входит:
- исправление ориентации страниц и компенсация наклона, вызванные невозможностью точного позиционирования, например, «толстых» книжек;
- разбиение на страницы отсканированных книжных разворотов;
- выделение «полезных» областей страницы — то есть отсекновение тех самых вкрапленных картинок, которые способны убить Cuneiform на месте;
- удаление пятен и прочих дефектов оригинала.
По умолчанию предполагается пакетная обработка в автоматическом режиме любого количества страниц, объединённых рамками единого проекта. Однако в случае, если результаты автоматики для какой-либо страницы кажутся неудовлетворительными, к ней можно вернуться на любой стадии исполнения и довести её вручную до желаемого состояния.
Каким образом всё это делается? Эта программа способна привести в отчаяние любого линуксописателя. Почему? Сейчас объясню.
Во-первых, она являет собой пример того самого интуитивно понятного интерфейса, о котором столько говорят большевики, меньшевики, проприетарщики и опенсорсники. Но примеры которого весьма редко встречаются в разработках рассуждающих на эти темы. При первом же взгляде на запущенный Scan Tailor у матросов просто не остаётся вопросов, что нужно делать дальше на каждом этапе — от создания нового проекта до фиксации его результатов:
Во-вторых, для тех матросов, у которых после рассмотрения интерфейса вопросы таки остаются, существует подробное руководство на языке родных осин, сопровождаемое списком часто задаваемых вопросов. Матросам, не в состоянии «асилить многа букафф», предназначено укороченное (но, тем не менее, вполне исчерпывающее) быстрое начало. Наконец, матросы, испытывающие идиосинкразию даже к малобуквию, могут воспользоваться видеоуроком.
Все перечисленные материалы, вместе с советами по сканированию, описанию подготовки DjVu-документов и руководству по сборке из исходников, можно найти на этой странице. И мне, как линуксописателю, добавить к ним почти нечего. Разве что продемонстрировать, как я применил Scan Tailor на практике.
Надо сказать, что первый мой опыт его применения — к страницам упомянутой ранее «Истории Шотландии», — оказался не очень удачным. Но вызвано это было не недостатками программы, исключительно торопливостью — я поленился вернуться к тем страницам, которые оказались исправленными на автомате не идеально — и в результате после распознания текста мне пришлось затратить немало времени на ручную правку.
Наученный горьким опытом, ко второму проекту — оцифровке монументального тома трудов Таджикско-Памирской экспедиции 1935 года, я подошёл с чувством, с толком, с расстановкой. Тем более, что к тому располагал и объём материала — без малого 1000 страниц с иллюстрациями, фотографиями, картами, вклейками и прочими атрибутами отчётов старой геологической школы.
Работа эта далека от завершения, так что пока просто для иллюстрации привожу первую страницу. Это — то, что получилось после сканирования, тот самый роковой для Cuneiform вариант с иллюстрацией:
А вот это — то, что получилось на выходе Scan Tailor’а:

Оно в дальнейшем пошло на распознание, о чём пойдёт речь чуть далее.
Распознание посредством YAGF
Как уже говорилось, использование Cuneiform… не то чтобы очень сложно, но как бы не комфортно. Кроме того, оказалось, что распознавание текстов — одна из немногих задач, где при наличии альтернативы в виде CLI или GUI, последний, даже при хороших навыках работы в командной строке, оказывается эффективней. Что достигается возможностью визуального контроля результата и интерактивного вмешательства на всех стадиях процесса.
В качестве графической оболочки для я остановился на YAGF — не вследствие предубеждения против Cuneiform-Qt, а просто так получилось, что о ней я узнал раньше.
Итак, YAGF — разработка Андрея Боровского, местопребыванием в сети имеющего вот этот сайт (контент которого, кстати, далеко не исчерпывается указанной программой). Основанная на библиотеке Qt4, эта программа распространяется автором в исходных текстах под лицензией GPL v3. А в бинарном виде доступна практически во всех распространённых дистрибутивах.
Программа YAGF — не просто оболочка для Cuneiform, а нечто вроде интегрирующего центра, позволяющего:
- сканировать страницы для распознания — посредством вызова программы Xsane;
- выполнять некоторую предобработку отсканированных страниц в виде разворота на 90 или на 180 градусов, а в последней версии — и коррекции наклона (впрочем, Scan Tailor это не заменяет и не исключает);
- собственно распознать текст одной страницы или любого их количества — лишь бы все они были предварительно открыты из файлов или отсканированы;
- выполнить несложное редактирование распознанного текста, вплоть до проверки орфографии;
- сохранить текст в одном из двух форматов — TEXT или HTML.
Как и в случае со Scan Tailor’ом, интерфейс программы и документация к ней оставляют немного места для творчества линуксописателя. Так что задержусть только на отдельных моментах.
Как я уже сказал, сохранение результата распознания возможно в виде плоского текста или html-файла. Однако собственно при записи выбора не предоставляется — он должен быть сделан раньше, через выпадающий список пункта Формат распознавания инструментальной панели. В чём разница между ними — я продемонстрирую чуть позже на примере.
YAGF умеет распознавать текст из любого количества одновременно открытых страниц, для чего на инструментальной панели имеется специальная кнопка Распознать все страницы. Однако «в лоб» прибегать к ней стоит только в случае однородного моноязычного текста, лишённого картинок. В противоположном случае имеет смысл сначала поработать с блоками — это здорово сократит объём ручной правки впоследствии.
В качестве блоков следует выделять однородные участки текста — например, чисто русского, не захватывая при этом картинки. В этом случае после нажатия указанной выше кнопки обработке подвергнутся опять-таки все страницы, но только те их части, которые были включены в блоки. Соответственно, пропадут ошибки, связанные с попытками распознать иллюстрации, во-первых, и не будет неправильно распознанных иноязычных вкраплений — во-вторых.
Картинки, разумеется, нужно проигнорировать. А вот иноязычные вкрапления (если, конечно, они достаточно велики — иначе овчинка не стоит выделки) можно, сняв предыдущее выделение, пометить в качестве новых блоков, переключить язык, распознать и вставить фрагменты в нужные места основного текста.
Правку свежераспознанного текста, с точки зрения ликвидации ошибок процесса, выполнять очень удобно: ведь мы в одном окне, в разных его панелях, видим и отсканированный оригинал, и результат его обработки программой.
А теперь на примере покажу, как всё описанное выглядит в реальности. Пугать читателя тем, что получается при распознавании плохо обработанных сканов страниц (или страниц с картинками) я не буду. Прошу поверить на слово — зрелище местами вполне душераздирающее. Хотя, как ни странно, из 13-ти страниц Истории Шотландии совсем безобразно распозналось всего 3.
Тем не менее, в качестве исходной страницы берём результат аккуратного исправления сканограммы посредством Scan Tailo. И при выборе формата распознавания TEXT получаем следующую картину:
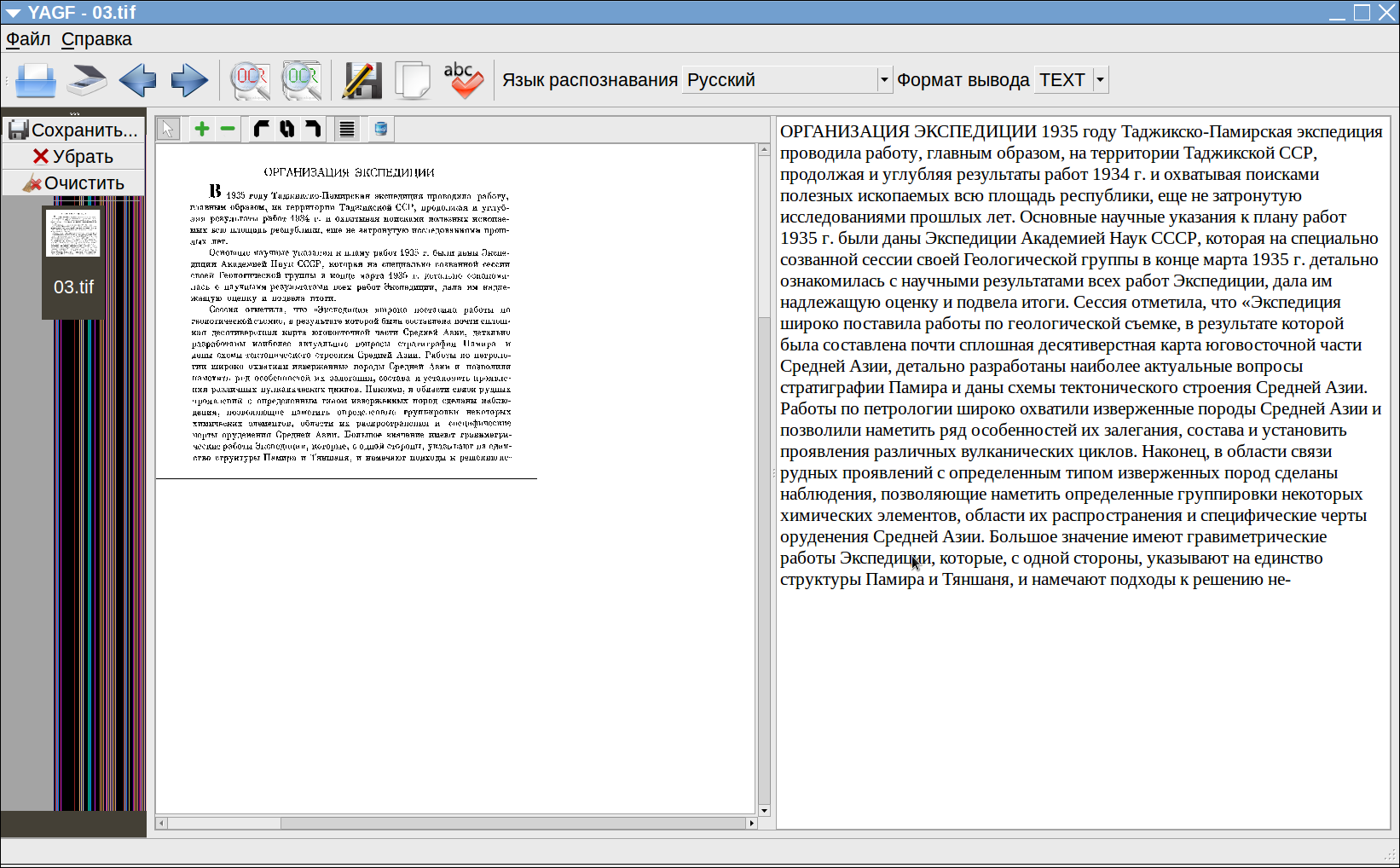
То есть распознано всё замечательно — кроме абзацев. Которые, конечно, в данном случае легко поправить вручную. Ну а если страниц таких — десятки или сотни?
Тут я методом ползучего эмпиризма выяснил, что если в качестве формата распознавания выбрать HTML, то результат будет таким:
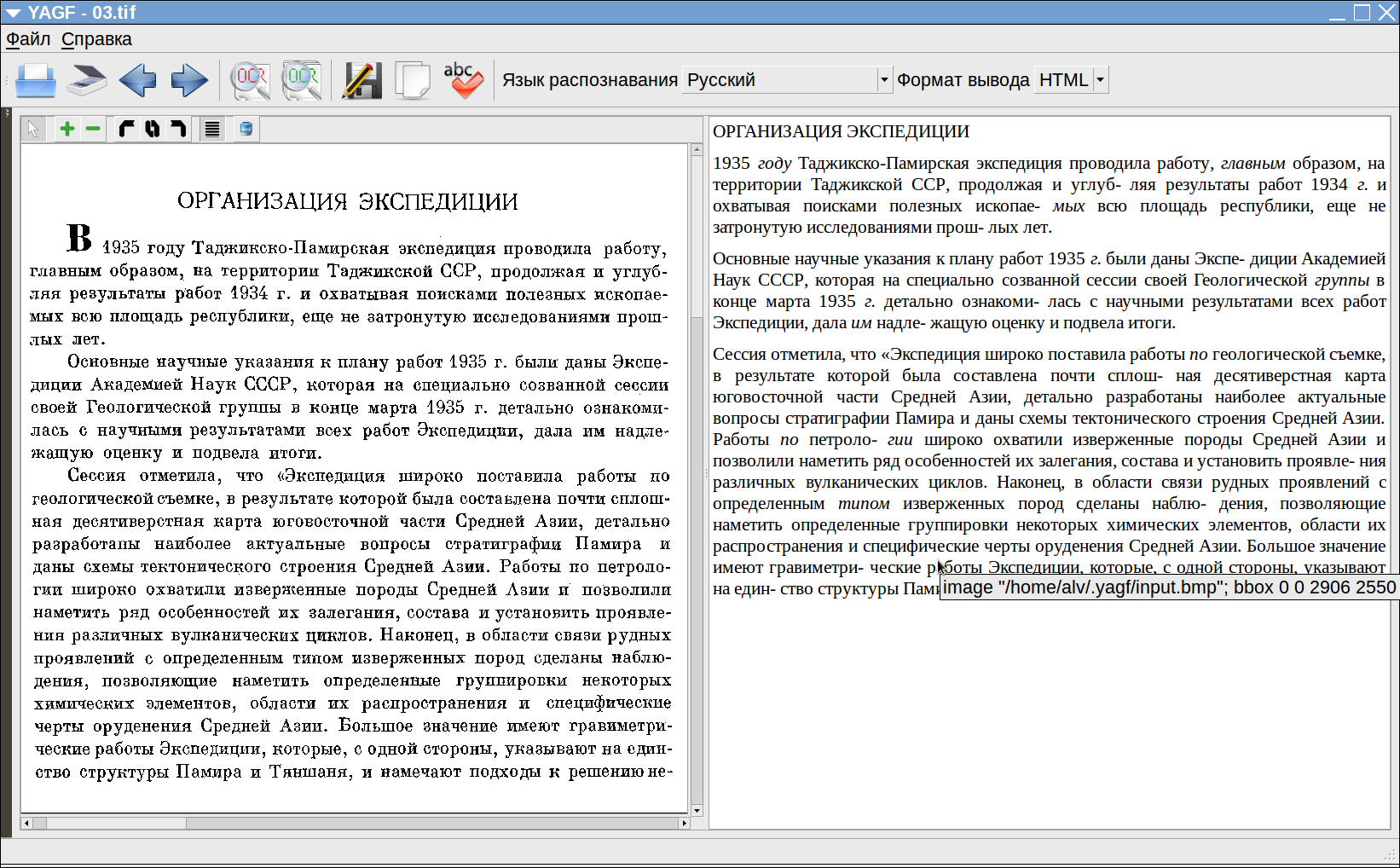
То есть — именно то, что прописано доктором. Правда, сохранить результат можно только в файле формата распознавания, а генерируемый YAGF’ом код весьма далёк от pure HTML. будучи открыт в текстовом редакторе, он выглядит примерно так:

Однако никто нас не неволит его именно в таком виде и использовать. Ибо можно скопировать его в буфер обмена (на панели есть для этого специальная кнопка) и поместить в любимый тестовый редактор уже как plain text с разбиением на абзацы. Ведь кое-какая правка (например, избавление от переносов) всё равно потребуется, а делать её удобнее специально предназначенным инструментом.
На свободу с tesseract
Описанная в предыдущих заметках методика распознавания даёт неплохие результаты. И, казалось бы, чего ещё желать, кроме дальнейшего совершенствования всех её компонентов? И, в первую голову, ключевого — то есть собственно «распознателя» Cuneiform.
Оказывается, есть чего. Разработчик YAGF, Андрей Боровский подчёркивает…
…что, в отличие от tesseract, Cuneiform – не полностью открытый продукт. Самого главного – тренера программы, который обучал бы ее распознаванию новых языков, мы так и не получили… Я решил от дальнейшего развития этого направления отказаться, так как считаю его практически неэффективным и методологически неправильным. Нам нужен русский tesseract, полностью открытый.
Так что резонно обратиться к этому самому tesseract’у.
По своему происхождению эта программа схожа с Cuneiform. Она была создана как проприетарное средство компанией Hewlett-Packard и активно развивалась ею до середины 90-х годов прошлого века. Затем ещё десять лет она была подобна тому самому сену, на котором лежала собака. После чего в 2006 году была куплена Google, от которой получила вольную под лицензией Apache 2.0 — в расчёте на её развитие силами сообщества.
Надо сказать, что расчёт Google оправдался: усилиями команды, разработчиков, главой которой выступает Рэй Смит (Ray Smith), уже в 2007 году была выпущена 2-я версия, а в 2010 — и третья. которая обрела способность работать с UTF-8. Это открывает перед ней возможность многоязычности. Последняя реализуется в качестве дополнительных языково-специфических модулей. Среди последних имеет место быть и русский.
Выпускаются тестируемые основной командой версии для Windows и Ubuntu Linux. Версии для прочих дистрибутивов собираются их майнтайнерами и имеют неофициальный статус. Как и версии для Windows с использованием CygWin и для MacOS X.
В «больших» дистрибутивах обычно имеется пакет tesseract и многочисленные языковые модули к нему, в том числе и русский (вида tesseract-langpack-rus или tesseract-ocr-rus). Так что для их использования остаётся их только установить.
Сам tesseract — это утилита командной строки. Формат соответствующей команды таков:
$ tesseract file.tif out_file -l rus
Где file.tif — имя файла отсканированной страницы (про поддержку более иных графических форматов — молчок), out_file — имя выходного файла (в формате plain text, суффикс txt к имени добавляется автоматом), опция -l определяет язык (в примере — русский).
О результатах можно судить по распознаванию страницы, приведённой выше:

Напоминаю, что она была предварительно обработана с помощью Scan Tailor. А потому для чистоты эксперимента её стоит сравнить с выводом «чистого» Cuneiform’а:
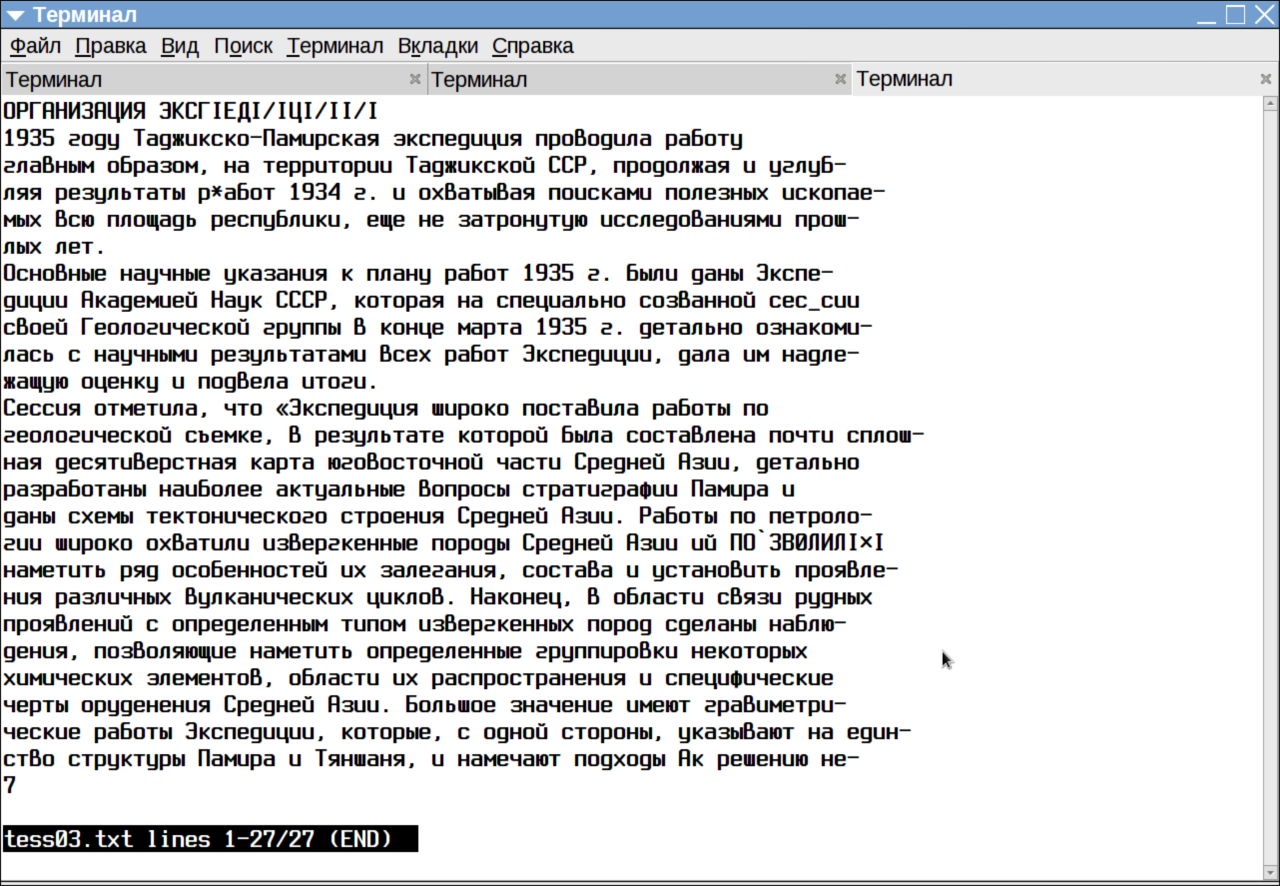
Как видите, ошибок при распознавании tesseract допустил, пожалуй, чуть больше. Но зато в текстовом формате он сохранил разбиение на абзацы и концы строк исходника. И ещё немаловажно, что tesseract не умирает при попытках распознать текст с картинками. Для сравнения даю результат распознавания той же страницы до её обработки в Scan Tailor:
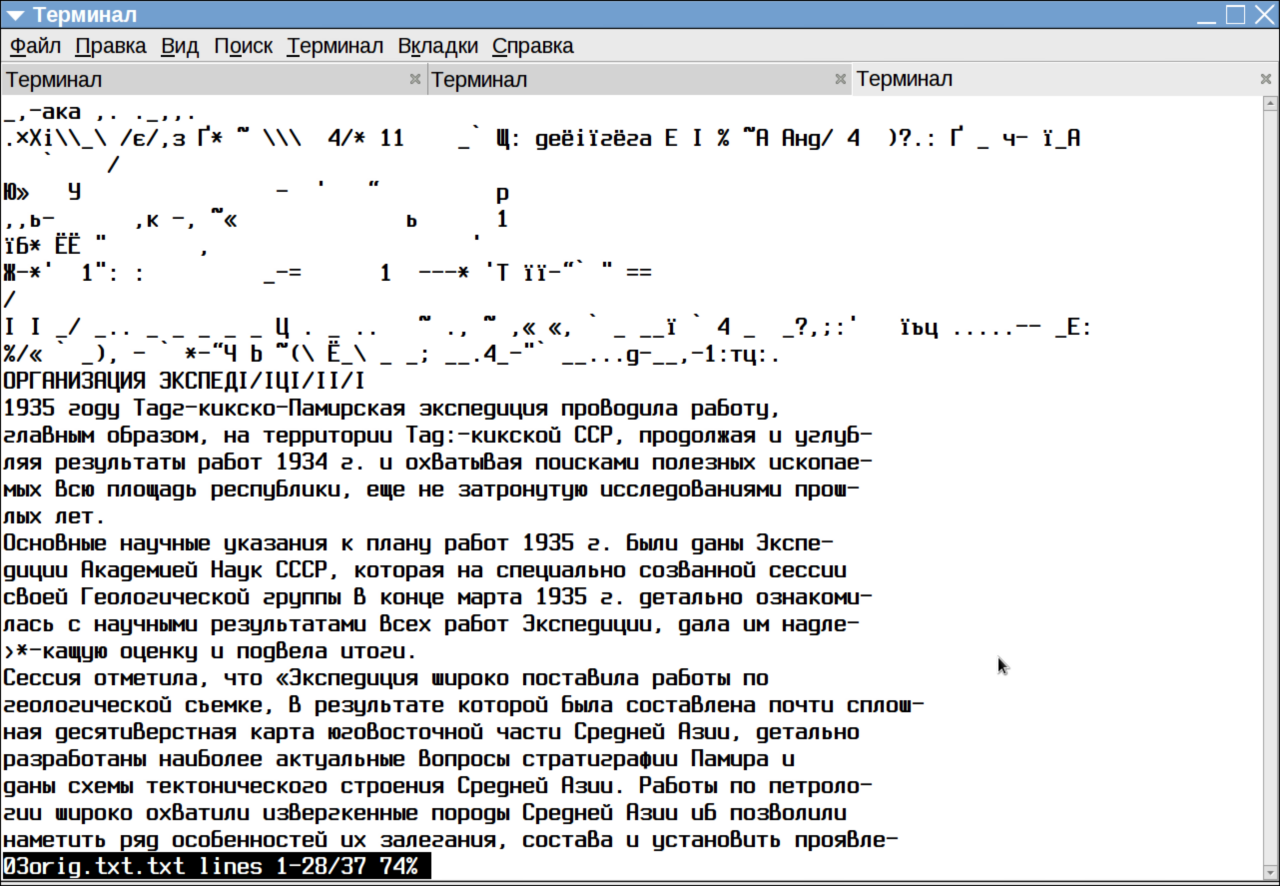
Разумеется, число ошибок увеличилось, но процесс распознания tesseract, в отличие от Cuneiform, смог довести до конца.
Кроме того, tesseract выполняет распознавание несколько быстрее, нежели Cuneiform. Правда, это могло бы быть ощутимым только при пакетной обработке.
Тем не менее, к использованию tesseract вполне пригоден для распознания единичных страниц. А свободный характер разработки и процитированные в начале заметки слова Андрея позволяет надеяться на дальнейшее его совершенствование.